2️⃣ Recognize signs of duplicate content/cannibalization in analytics tools
3️⃣ On-page content optimization
4️⃣ Appropriately implementing 301 redirects
Content consolidation is valuable because the results come quicker than creating new content
When you create new content, Google has to take time to crawl, index, and rank your content.
Consolidation, on the other hand, is essentially a type of content update.
Because the URL you’ll be using likely has existed for quite some time and is already associated with your target keyword(s), the results often come quickly.
Below are some examples of how fast consolidation efforts can bring results:
The other beautiful part of a content consolidation project is that you combine so much content and data + new conversation points in a way that allows the potential traffic to increase dramatically as time goes on.
Below you can see that there was a dramatic jump in performance immediately. Then over time, as the number of queries this post qualified for expanded, traffic grew for six more months.
Thanks for reading The SEO Trade School! Subscribe for free to receive new posts and support my work.
What causes the need for consolidating content?
Content consolidation in the SEO world is recommended when 2+ pieces of content are so similar in their messaging/intent that Google’s algorithms have difficulty deciding which one to display on the SERPs.
Brief history: A long long long time ago, before Coronavirus, websites could rank multiple pages on the same SERP (aka for the same keyword). Meaning a company like Hubspot would often have positions 1 and 2, blocking out competitors.
Google decided they didn’t want this experience for their users, essentially saying everyone should get a max of one spot on the SERP. So they launched a new update to their algorithms to help make this a reality.
This has more or less been effective (although we’ve all probably seen a time or two when the same site snags two spots on the SERP)
And even more recently we’ve seen the indentation of related content on the same SERP (image below)
Anyway, the point is, it wasn’t always this way and now it is - so we need to understand content consolidation.
Two terms you’re going to hear in conversations regarding content consolidation:
Duplicate content - Duplicate content is what the industry decided to call content too similar to another piece of content. It creates complications related to ranking.
IMPORTANT NOTE: There is no such thing as a duplicate content PENALTY!
There is a big difference between a manual action penalty and simply not ranking as well as you could because the algorithm struggles to sort out your content.
Cannibalization - Refers to the actual complication of having duplicate content.
When two or more pieces of content compete for the same keyword/intent, they often prevent each other from ranking as high as possible.
SEOs will say, “these posts cannibalize each other because they’re effectively duplicate content.”
Your next question might be, why does this happen if SEOs know about it?
Duplicate content happens for a myriad of reasons, but here are the most common ones:
The company started creating content for the search engine long before quality mattered to the algorithms and the competition was less intense.
This usually meant creating hundreds or even thousands of 500-word blog posts that were often very similar.
Over time, as quality has increasingly become a ranking factor and because search intent for keywords constantly evolves - the related posts eventually start to compete with each other where they once were not.
As an SEO (even a very skilled SEO), sometimes you fly too close to the sun when creating cluster content for your pillars.
You might see two keywords that aren’t generating any related articles, and a basic SERP analysis tells you that you’re okay to create separate pieces of content to target both.
However, shortly after publishing - you’ll notice that the keyword intent of the two targets has seemingly merged, and the two pieces are better off being one to prevent them from competing.
Technical mishaps can cause duplicate content errors.
For example, perhaps your entire website lives on www.mysite.com/ and suddenly a new dev comes along and says, “let’s update the website so that it no longer lives on the ‘www’ subdomain.”
So the website is published again on mysite.com/ —> If not properly handled, you effectively end up with two versions of the same website being indexed by Google.
E.g. You might have the same blog post at:
www.mysite.com/blog/cannibalization-guide
mysite.com/blog/cannibalization-guide
How do you recognize duplicate content on your website?
You can watch for duplicate content and consolidation opportunities in several ways.
They range from hunting for them in your analytics tools to accidentally stumbling upon them.
Noticing when high-performing content decays exactly as a newer piece of content begins to grow
If you recognize that a new piece of content is starting to perform very well —aka impressions shot up for that URL and yet growth on the website or the blog can’t be seen - it can be helpful to check for impression losses on other pages.
Likely another post is beginning to see unexpected decay due to this other post’s prioritization by Google. If your new post discusses a similar topic, you have a content consolidation opportunity.
Side note: If you’re confident that the two pieces can co-exist, sometimes the best plan is to wait a couple of months. There are times when Google will sort out the different of intent between them.
You can also insert internal links between the two pieces to show their relationship to one another to help Google better understand what you’re targeting with each.
Google might just be parsing things out in the background, and the two pieces won’t impact each other for too long.
Stumbling upon these opportunities as a result of strategy
I know this sounds incredibly strange or lazy, but if you work in the industry and on very large content websites, you only have so many resources/much time to optimize everything.
Aka, you’re not always out looking for cannibalization.
And sometimes, overall growth is so significant that it might not be apparent that some pages are experiencing losses due to cannibalization until you dig in.
A real-life example:
I once worked with a client whose ICP were eCommerce companies. The holiday season was coming up quickly, and they wanted to talk about Black Friday and Cyber Monday.
That conversation was the starting point for saying: “okay, let’s see what we’ve talked about related to this topic in the past and how much content related to this we’ve already produced.”
I was looking for the content we could update to get the quickest wins before jumping into brand new content that would need more time to rank.
***I also wanted to see if this content historically had data that it performed with its audience beyond receiving organic traffic - like conversions from distribution or search in the past.
The process for identifying the duplicate content looked like this:
Step 1: Google search command site:[yourdomain].com [insert topic/keyword]
Perform a site command for your website and the topic you’d like to cover to see how many pages on your website are related to that topic.
When I did this for the above client, we found that they had a whole host of content about Black Friday, none of which was ranking on page 1.
Step 2: Copy the URLs for the articles and paste them into Google Search Console
To understand whether the content is not ranking because it is thin or competing, begin looking through your content queries for each URL in GSC. You’re looking for any common keywords that that content shares.
For the above example, a single query appeared across multiple URLs.
Step 3: Filter your GSC data by “query” for your keyword and then look at the pages tab
To see which pages receive impressions from that keyword over a relatively short period, simply filter your GSC data by the query.
Then navigate down to the pages tab (since you’re only looking at a single query, the query tab won’t tell you much of anything).
Here are the number of pages within 3 months that Google thought shared the intent of that same keyword.
That signifies that these URLs are ripe for some content consolidation.
If you burrow down into the individual pages around this query, you’ll see many shifting impressions between URLs and rankings seemingly appearing and disappearing.
One day, Google will rank one URL; the next day, it might decide that it thinks another is better.
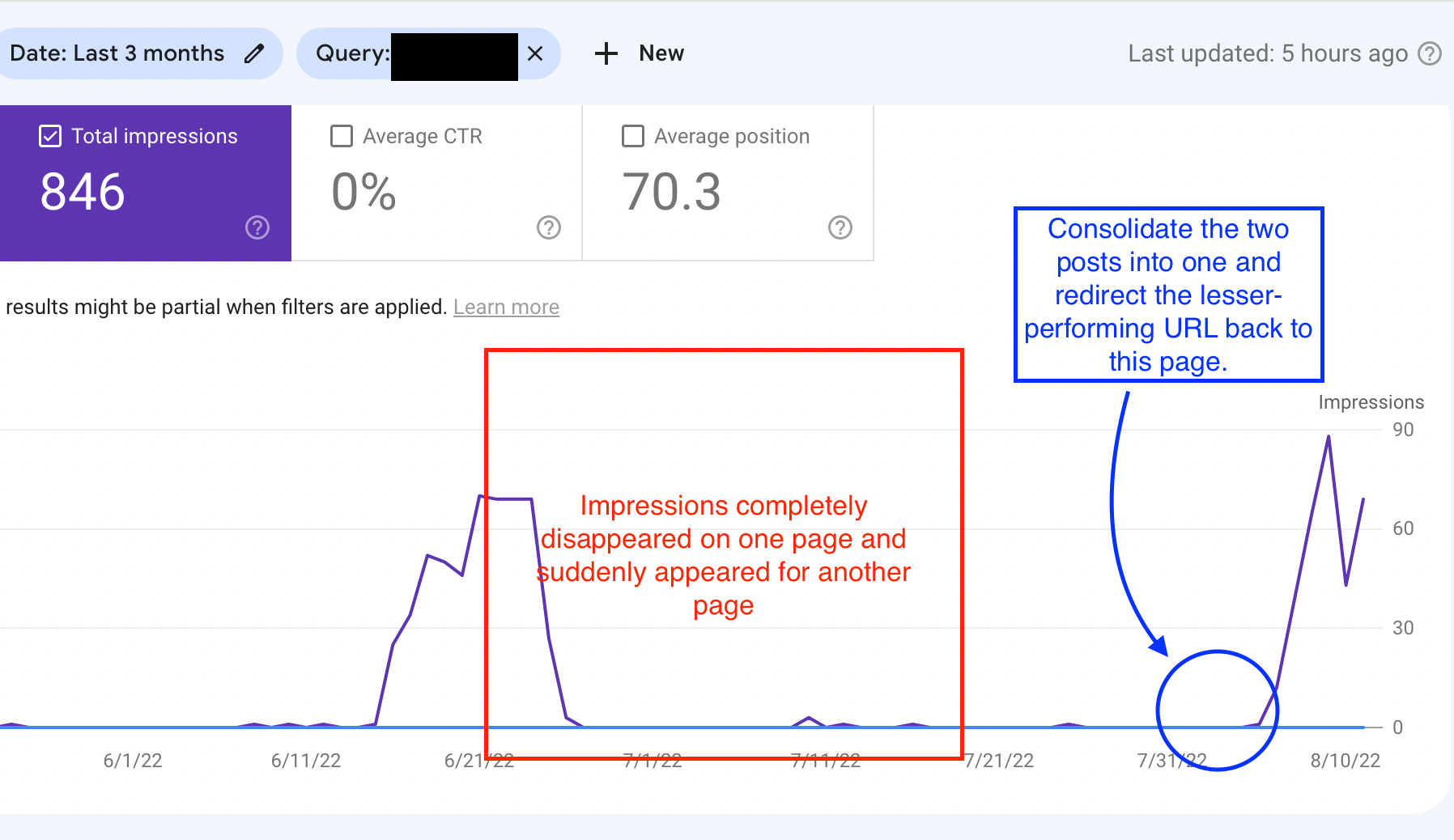
Here is what it looks like on the individual URL level:
Notice how this URL seems to have a position associated with this query some days and then completely disappears other days. That’s a pretty good indication that Google is confused.
Side note: You’ll see a similar patten happen when you publish new content and Google is just starting to have a clear understanding of where it belongs.
If a piece of content is new, and you see the above data, it doesn’t automatically mean you have a duplicate content problem.
If the content is older, however, it’s worth checking in on to see what is hanging it up from performing as best it can.
Using third-party tools like Ahrefs
Although not my favorite way to identify cannibalization, if you live in third-party tools —> you’ll notice that they often are capable of showcasing when it might be happening.
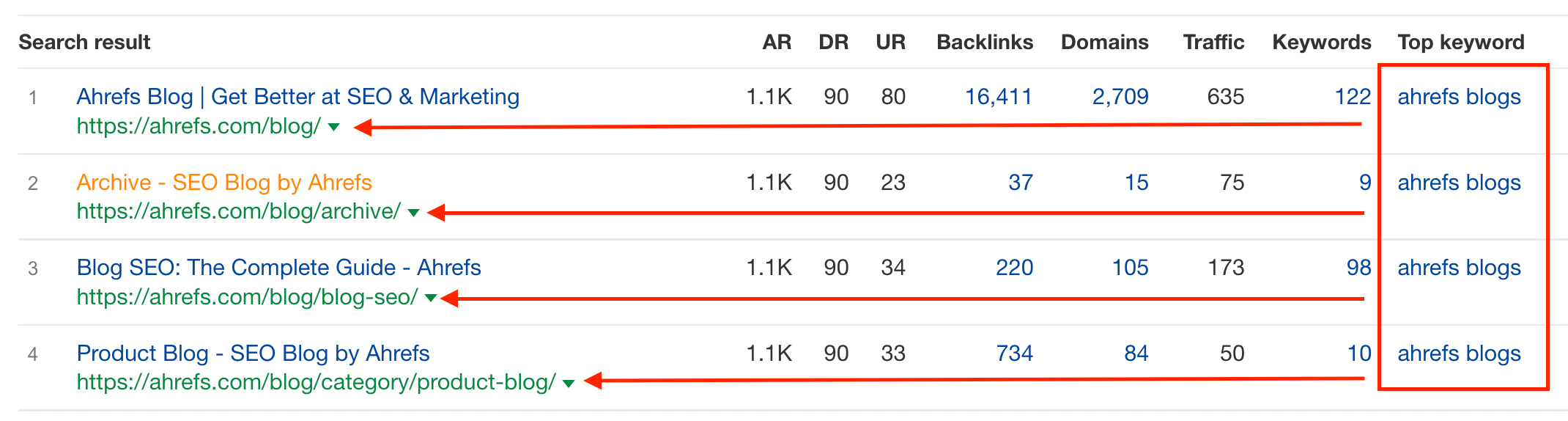
In Ahrefs, they make it super simple. From the organic keywords report, simply toggle on the “Multiple URLs only” switch.
This will tell you when you have a single keyword generating impressions on multiple pages (see image).
Important side note: It’s important to understand when pages sharing a query is normal or why it might happen and not need fixing.
If you look up most company homepages with a brand search, like “ahrefs” - you’ll likely see a SERP result like this:
If you’re in GSC or in a third-party tool, the URLs to the pages in the red box above will also generate impressions for “ahrefs”. This is perfectly fine, and is not a cannibalization problem.
The same can be said if a URL from one page ranks on page 1 and other URLs appear in SERP features like video, image, or Twitter carrousels. This isn’t necessarily cannibalization — but the tools might show you that multiple URLs are generating impressions for the same keyword.
Identifying consolidation opportunities at scale with GSC
If you have 100s or 1000s of blog URLs on your website and want to quickly narrow down where the potential is, you can do a bit of filtering and a bit of manual work.
You can start by searching GSC for queries that meet the following criteria:
Are not brand queries
Have a relatively high number of impressions
Hold an average position between 20 and 50
Have a CTR below 1%
This will give you a list of your high-potential queries:
Sometimes, to make sorting and filtering easier, I’ll export this list to a spreadsheet:
Now using Google Search Console, you can take your list of possible queries and investigate each one the way we did earlier in this newsletter issue. This is a manual process.
Filter by query
View pages report
If multiple pages appear, check for consolidation
Keep going until you have a full list of consolidation needs.
Your list should include the query causing the duplicate content problem and all the impacted URLs.
1. SERP & competitor analysis - Look up the query causing the cannibalization problem. Evaluate the intent and context of each piece. This involves looking at the headers, the title tags, and the content of the top ranking pieces to see what a great page should, at a minimum, include.
For detailed instructions on how to do this, I’ve laid them out in these two previous newsletter issues:
2. Review the URLs cannibalizing for the target query - Read through the content from each URL that generates impressions for the same query. Your goal is to identify the unique parts of each post that can be used to satisfy the intent you identified in your research in step 1.
Purely hypothetical example:
Perhaps your company created 4 blog posts about using marketing automation for email campaigns.
Post 1 = what email automation is and the reasons marketers use them for email campaigns
Post 2 = discussing 5 types of email automations available to marketers
Post 3 = best practices and common mistakes when using email automation
Post 4 = your favorite tools that allow you to set up email automations
After you look at the intent for your target query (the one that’s causing the cannibalization), you notice that page 1 is only large guides that include all of the above topics.
You’ll need to combine all 4 of those posts with the most relevant information from each that help you match the intent.
3. Combine and create your new and improved Frankenstein post - Next is the actual work of bringing all that content together in a smooth, well-written article that does not feel like four posts that were simply copied and pasted together.
You’ll also need to include any other sections required to create a thorough piece that your posts might be missing that competitor posts feature.
*** Please don’t forget about ICP positioning/needs and SME notes!
4. The technical part (2 options) | implementing redirects - You have your finished article. Now you’re ready to go back to GSC and look at the impressions of your competing URLs over the same query (see below image).
The screenshot shows that one URL receives significantly more impressions than the rest for your target query.
Look at the URL slug associated with the most impressions. This is where we have two unique options that we can take. ***Both are fine, but one feels more secure if available.
Option 1: If that URL slug as it is written is still relevant to the intent, you will update that URL with the content of your new and improved post. You choose this URL because Google already understands it to be MOST aligned with your target keywords intent (this ensures quicker ranking improvement results).
Upload your content and update the publishing date.
Now, for all the other URLs you identified as competing, you will set up 301 redirects to the URL you just updated.
Option 2): If that URL slug and the remaining slugs as they are written are no longer accurate or relevant to the intent, you can publish your consolidated post on a completely new URL.
You’ll then 301 redirect all previously existing URLs that competed for the same target query to your brand new URL.
It should have the same impact as option 1, but sometimes signals get lost in Google's algorithm shuffle. It’s rare, but it happens.
Example of a URL that you might choose not to use:
Let’s say the top URL for impressions of our target keyword is:
The above URL contains a specific number that might no longer be accurate. Perhaps your updated version has only 7 best practices included (or now has 12).
It also contains an old date in it from years ago that might lead Google or readers to believe that this is old information.
In this case, the URL with the highest impressions isn’t a great option to use. Either use one of the other current URLs associated with your keyword or create a new, accurate, and fully optimized URL.
5. Wait for the results to come in - all that’s left to do is wait and watch for your results to come in!
Thanks for reading The SEO Trade School! Subscribe for free to receive new posts and support my work.
Thanks for reading, and feel free to share with anyone else you think would find this helpful
I’ve received a lot of great feedback from you all about the usefulness of these articles.
The support has been overwhelming from being featured in newsletters, shared in company slack channels, and used in onboarding for new SEO staff.
This is meant to be a free resource for learners — one that I wish had existed when I first started (without a mentor at my side to walk me through these learning lessons).
And if you found this piece useful, I highly recommend checking out these previous walkthroughs for more beginner learnings:
















Los mejores muebles en Bucaramanga se encuentran en https://www.jamar.com/ Entra y sorpréndete